Năm 2020, bên cạnh cuộc chiến khốc liệt với virus Novel Corona (nCov), vẫn dai dẳng và mãnh liệt cuộc chiến chống tin giả, tin quá sốc, tràn lan trên các mạng xã hội.
Trong các loại tin giả, có không ít tin được đưa theo hình thức chụp ảnh màn hình điện thoại, chụp trình duyệt trên máy tính để làm bằng chứng. Ảnh màn hình điện thoại dễ dàng làm giả với một lập trình viên mobile, còn với ảnh trình duyệt, ai cũng làm được, không cần tới trình độ PhotoShop đỉnh cao hay kỹ thuật lập trình chuyên nghiệp cỡ như các Pymiers.
Bài viết sẽ vạch trần kỹ thuật làm giả này, đồng thời lợi dụng nó để crawl dữ liệu ngay trên trang web, dùng chính trình duyệt mà không cần thêm gì khác như BeautifulSoup4 hay requests-html.
Web page là gì
Web page là trang web, sử dụng HTML để biểu diễn cấu trúc.
HTML là gì
HTML là một ngôn ngữ markup (đánh dấu), dùng để mô tả cấu trúc một web page. Nó sử dụng các tag (thẻ) để đánh dấu. Chuột phải vào màn hình, chọn "View page source" để xem code HTML của web page.
HTML không phải một ngôn ngữ lập trình (programming language).
HTML tag
Mỗi bộ phận của web page được đánh dấu sử dụng một cặp thẻ tương ứng, <a ...> </a> để đánh dấu một web link, <table> ... </table> để đánh dấu một bảng ...
Xem đầy đủ các tag tại đây
Document Object Model (DOM)
Document Object Model (DOM) biểu diễn HTML ở dạng cây (tree structure). DOM là programming interface cho HTML (và XML) documents.
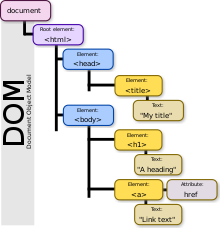
Sử dụng cây này có thể dễ dàng truy cập (query) các thành phần của web page, thay đổi chúng (manipulate).
Mỗi web page là một document.
Truy cập & thay đổi DOM trên trình duyệt
Mở một web site ra, rồi bật web console lên, hoặc đọc bài này nếu chưa biết cách.
Document, Window & DOM Elements
Mỗi web page là một document, mỗi "cửa sổ" (thời nay là 1 tab trình duyệt), là một window, đại diện cho cửa sổ đó. Mỗi document là một tree, với các node gọi là các Element.
Gõ vào web console document, đây chính là DOM của web page đang truy cập, thông qua object này, ta có thể làm đủ trò với những gì đang hiện trên trình duyệt.
Get element
Có vài cách để truy cập element, trong đó kể tới 2 methods:
document.getElementsByTagName: lấy các elements theo HTML tag của chúngdocument.querySelectorAll: lấy các elements theo CSS selectors.
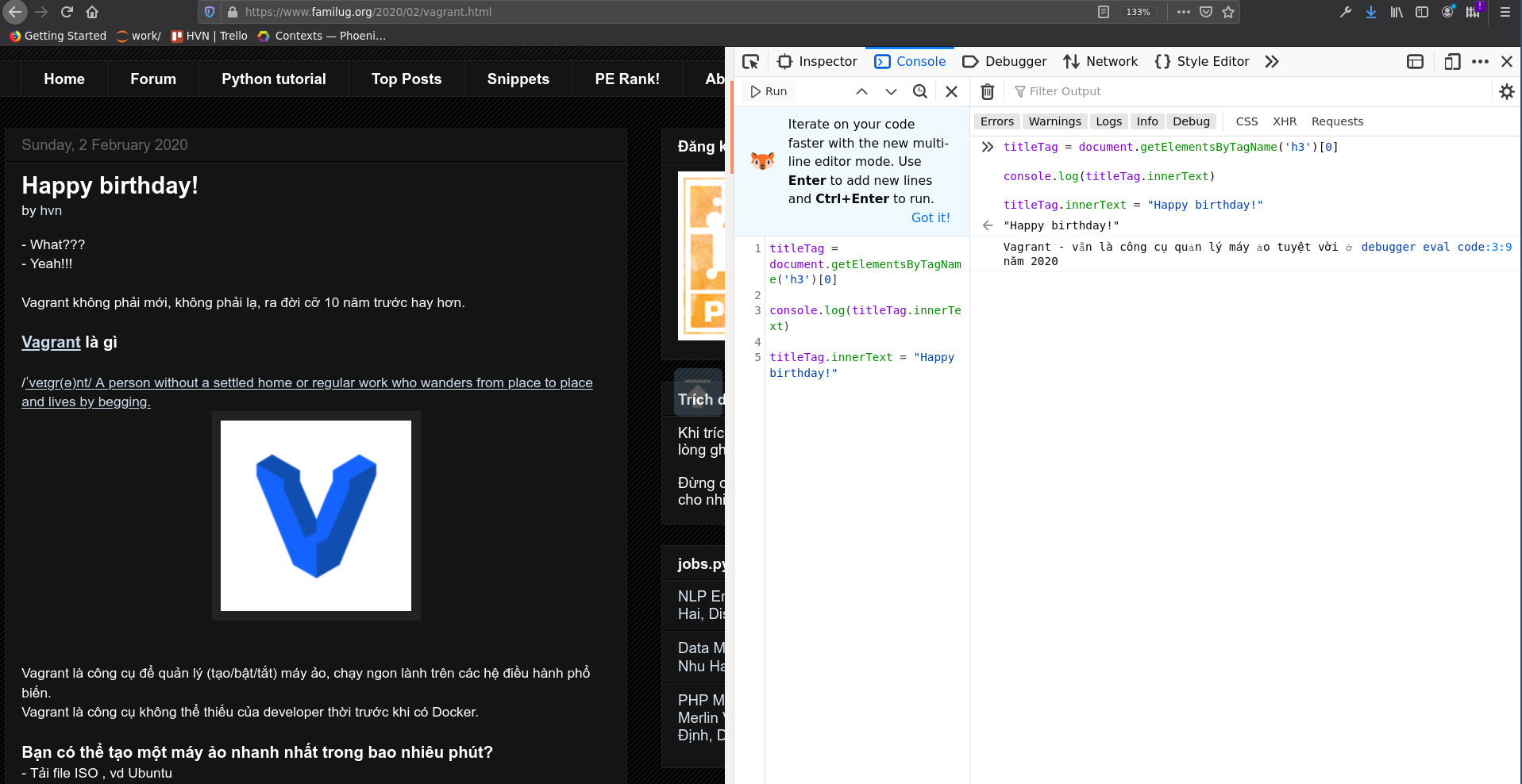
innerText là thuộc tính (attribute) của một element, chứa nội dung text của nó. Ví dụ sau sẽ thay đổi tiêu đề của bài viết, đây là cách làm tin giả rồi chụp mành hình, không cần dùng PhotoShop:
Vào web page: https://www.familug.org/2020/02/vagrant.html
Sau khi "hack"
titleTag = document.getElementsByTagName('h3')[0]
console.log(titleTag.innerText)
titleTag.innerText = "Happy birthday!"
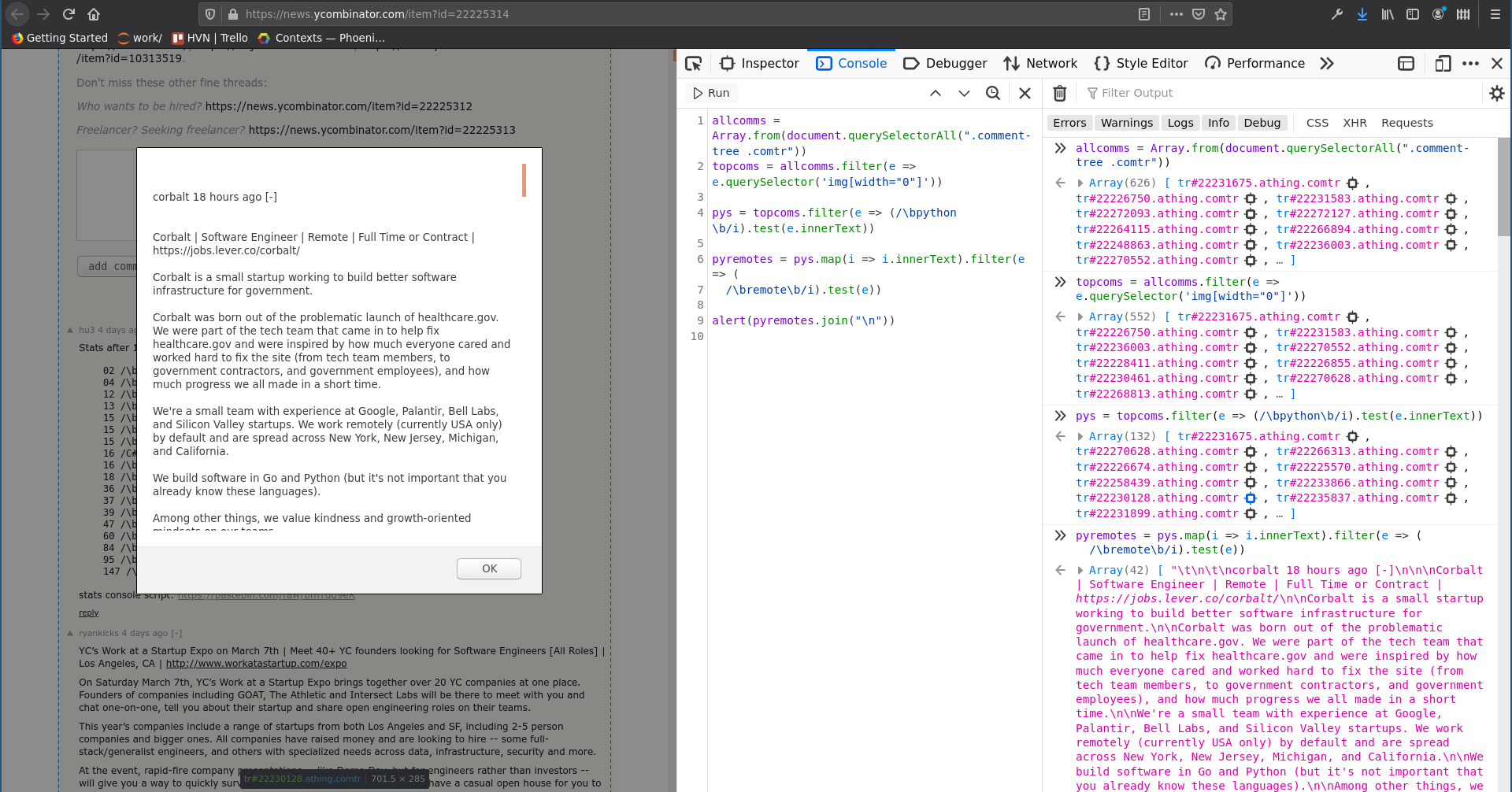
Query element
Thay vì dùng HTML tags, có thể dùng CSS class để tìm ra các element, ví dụ sau đây tìm các tin tuyển dụng trên trang HackerNews có chứa từ khóa Python và Remote, rồi hiển thị lên màn hình - có thể xem như crawl dữ liệu ngay trên trình duyệt:
allcomms = Array.from(document.querySelectorAll(".comment-tree .comtr"))
topcoms = allcomms.filter(e => e.querySelector('img[width="0"]'))
pys = topcoms.filter(e => (/\bpython\b/i).test(e.innerText))
pyremotes = pys.map(i => i.innerText).filter(e => (/\bremote\b/i).test(e))
alert(pyremotes.join("\n"))
Đoạn code trên học theo một comment trên HackerNews
Đọc thêm về map/filter tại đây.
/\bpython\b/i là Regex Object, dùng để tìm các đoạn text chứa từ khóa Python, chữ \b để đánh dấu boundary, tức kết quả sẽ không chứa pikapython mà chỉ chứa pika python, i để không phân biệt chữ hoa chữ thường.
Kết luận
DOM là khái niệm cơ bản về web page, là nền tảng để lập trình JavaScript ở phía client (trên trình duyệt), dù không phải Front-end developer, cũng nên biết dùng DOM, để automate, để "hack".
Happy new year 2020!
Comments